

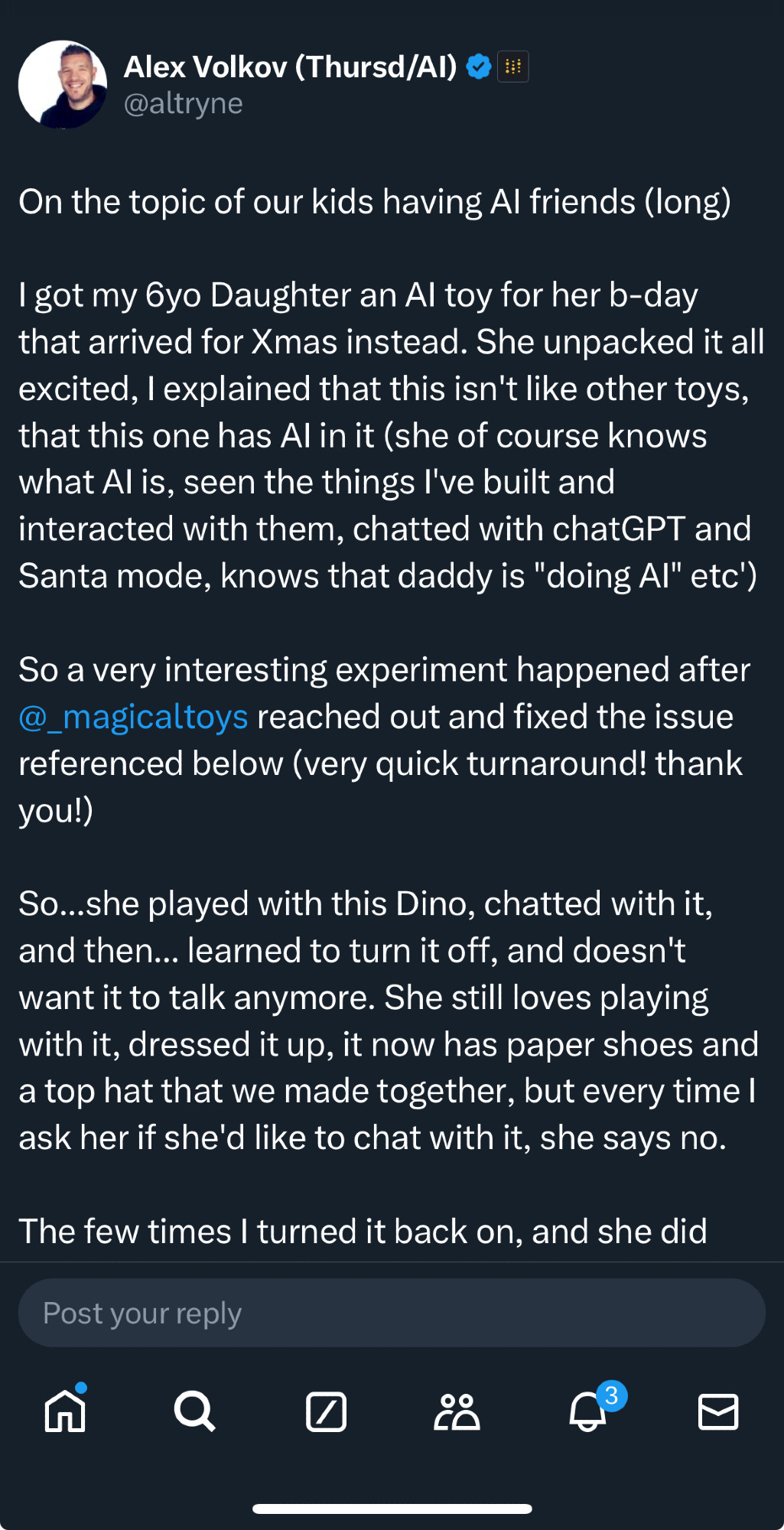
5·
2 days agoyou: how do i turn off gemini
gemini: i drink your data milkshake :)
you: how do i turn off gemini
gemini: i drink your data milkshake :)

BEEP BOOP WHAT THE FUCK
superb sneer in the YouTube comments
@monx 36:10 Mikey hints at the central contradiction of his vision. love that he sees music as more than background noise. But this kind of “interchangeable commodity” is exactly what generative Al produces. It’s similar to a fantasy where you’ll type 'painting of a beautiful sunset" into a machine and then have the output hung in the Guggenheim, as if you made any meaningful contribution, as if the interpolation of training data (infinite in supply) would be special and meaningful to people. We will not escape the tautology that generative art is cheap. This can only be resolved by adding more and more degrees of creative control to the input - controls that demand more skill from the operator - until, finally, we arrive back where we started.
would love to read more from this person
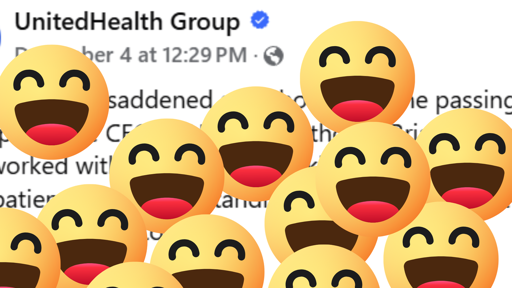
this is just so nakedly a scam, it’s a little startling. I feel like if your whole pitch - as it appeared to me - was “we will be like the tories but more competent and less corrupt,” then it would behoove you to at least try to appear more competent and less corrupt
Another thing I’ve found actually works pretty well is setting up two computers next to each other with ChatGPT voice mode, if you give them custom instructions to be sure to wait for the other one to be done talking, they don’t interrupt each other and can get quite a bit of work done. Here is just a video of the mvp that I sent to a friend ages ago once I started playing with the idea: https://s.h4x.club/kpuzNkNL - I actually use this method of working quite often now, couple times a week at least, I find it’s pretty helpful. If I knew how to put 4/5 modals together in one app and give them each custom instructions, I’d love to try building a team (if someone out there actually knows how to build this kinda stuff, I’m happy to help flesh out how the product would need to work, but I don’t think it’s super difficult to build at this point, I’m just not technical enough)
you must click the video link
this is going in hard enough that I suspect zuck is not expecting there to be another meaningful election
been binging the your kickstarter sucks archives and this post is giving me deja vu
THANK YOU. I feel the exact same way, word for word, although my feelings are directed at juicero rather than openai. sick of the juicero naysayers who don’t understand
please explain to us how you think having less, or more, subscribers would make this profitable
I’m an AI researcher
*jerking off motion*
why are none of these people working on 3d printing guillotines. reading this blog post, there’s clearly a use case
“I don’t know what this is, here’s my reaction to what I thought the topic was, no I didn’t read the article or lurk”
bizarre that they actually just say this
read through some HN comments the other day and felt so intelligent by comparison. I’m kind of a dipshit so don’t get that feeling many places. just there and /r/adviceanimals really
ok. this stackexchange answer suggests “at least” 810 gp as the cost for a wizard to cast wish.
the cost of gp has little relation to that of modern currency. but in DND settings a goat costs one gp, and I am just going to bullshit and say goats are roughly as valuable irl as they are in the vaguely 18th century englandish default vibe of dnd. based on this goats as a store of value theory, we need to pay the wizard at least 810 goats.
now the cost of a goat depends greatly on its age and type, but we can guess that the cost of an adult dairy goat will be about 750 USD: https://rurallivingtoday.com/livestock/how-much-does-a-goat-cost/
in Australian dollars, the cost comes out to about $13,000. we now need to consult an Australia expert. @[email protected], is paying a wizard 13,000 Australian dollars to cast a tik tok protection spell over Australia a superior deal to paying an ai company however much to detect age from hand motions?
so openai is claimed to be doing great on the FrontierMath dataset. I’ve already seen the usual sort of dipshits using this to pump ai on reddit, and here’s a post that went to the frontpage on HN:
https://xenaproject.wordpress.com/2024/12/22/can-ai-do-maths-yet-thoughts-from-a-mathematician/
(tl;dr only a few problems from the dataset are public but if representative the problems are about 25% survivable by an undergrad; coincidentally this is the % openai says their models are completing.)
this post is by kevin buzzard. he has a let’s say not easily beloved personality, but I don’t think of him as credulous or grifty, and people in his area regard him as an excellent mathematician.
he points out but I think does not focus enough on how discrediting the secretive nature of the dataset is. the fact that you can’t make it public is necessary to run such experiments in a scientifically reasonable way, but also makes it totally impossible to run the experiment in a scientifically reasonable way. an experiment which cannot be examined or reproduced is actually the opposite of science. it’s pure grift fuel
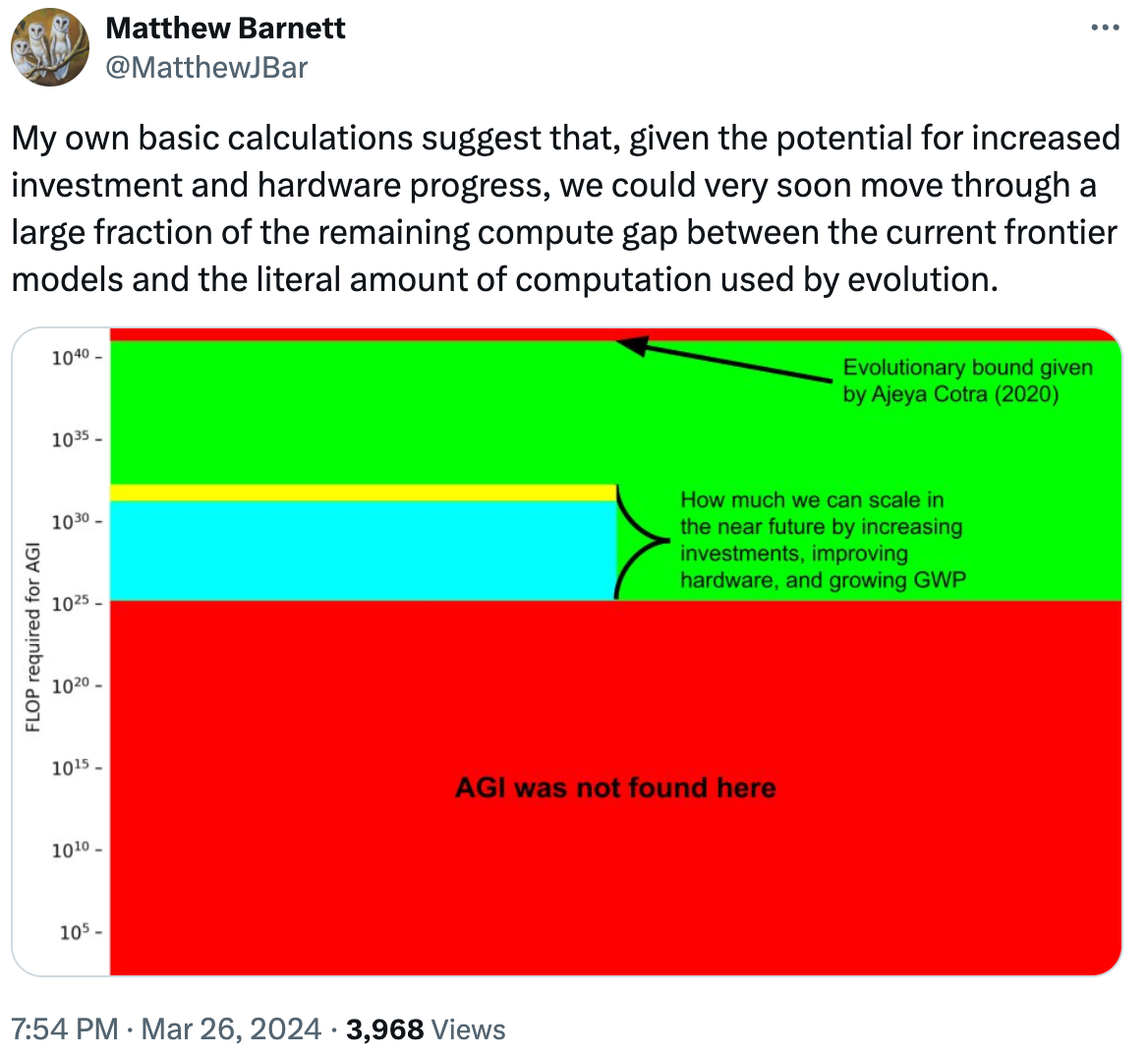
do you have any thoughts on why these wealthy and powerful public figures have all chosen this extraordinarily unusual aesthetic
very interesting, thank you for sharing










{kind=link}
{kind=link}
{kind=link}
{kind=link}
1000 out of 1000 mengeles agree