
{kind=link}
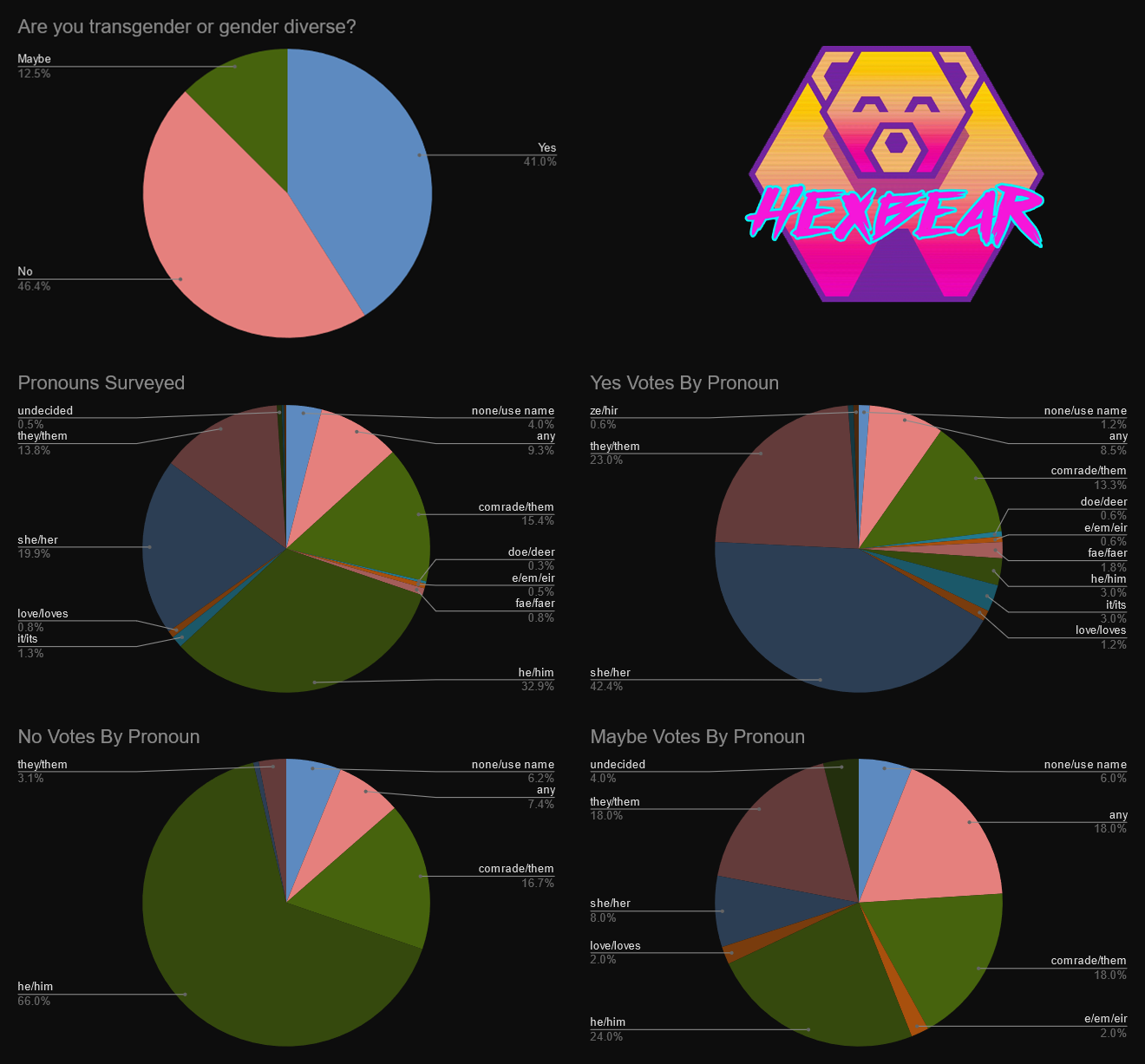
Took me a bit and I am a little drunk but here are the totals. We had a good showing.
Note: some comments got cut out because the server doesn’t like displaying more than 300 from what I can tell. I did my best with what it would show, I just sorted them by new. This should be fairly representative of the currently active userbase. As an aside, I believe we did a similar survey a looong time ago, and we had only 33% of the active userbase as trans.
Random thoughts:
A lot of people were very very cute and confused and essentially asked me to decide their gender for them. Eggs? Probably. This isn’t Harry Potter and I’m not a hat so I just went with what they were sounding more convinced of.
A lot of people are even cuter and don’t understand how to follow instructions, though some of this is my fault. Made this a little harder to organize.
Some people were not cis and did not identify with the words ‘transgender’ or ‘gender diverse’. If I ever do a trans/adjacent survey again, I think I will ask ‘Are you cis?’
I may do a survey for queer people overall eventually, and the question will be ‘Are you cishet?’
I would love to do more scientific, inclusive polling and have better and more questions and options, but we need some good secure polling tech for that, which we don’t have. So I just have to ask simple questions and get a handful of answers.
Next time I will look into how feasible it is to post a couple of comments and get responders to upvote certain ones. This might fix the issue of the display of comments being limited.
Since some people have two sets of pronouns, both of their pronouns are included separately.
Since the poll was public, some marginalized groups probably shied away from answering. If we ever get a secure way to poll people, we would get more realistic estimates of the trans and cis women userbase.
#Tallies
Yes: 121
No: 137
Maybe: 37
Total: 295
If you think something is fucked, you can do it yourself, the thread is public. Hope you like pie! 
Think this’ll work for the current survey?
I modified it a bit for the current survey:
This is the output:
 -----  ----- Hexbear has more lgbt people than the liberal lgbt instances and it's not even trying.   The one neat trick: Visible pronouns that aren't buried in a performative section of the profile page where people can ignore that they exist. -----  what is this honeypot ----- i’m not cishet i am the opposite of that -----  ----- Yes I can't do hexbear emojis on my phone -----  ----- No ----- dean-smile: 97 dean-frown: 174 dean-neutral: 23 dean-malice: 5 total comments gone through: 308 total comments skipped: 31I’m not sure what happened to the comments neither gone through nor skipped (I’m skipping replies)
Thanks, I’ll take a look at running it when we’re done collecting. I’m probably gonna have to comb over some answers that didn’t complete the survey properly
Is there a way to just download the json? I’ll probably just edit a text file and load it into your code
Just download the JSON from the API? Sure. Something like this:
I also realised what was wrong! range() is inclusive-exclusive, that means for 1 to 8: it should be (1,9).
Thanks for the help
Yes, or with very little changes.