
Chlorocruorin is really confusingly named. I was trying and failing to find the chlorine in it and was wondering if I was just dumb or blind or what.
khloros is Greek for “green”. That’s also where chlorine gets its name. So they’re only related etymologically.









{kind=link}
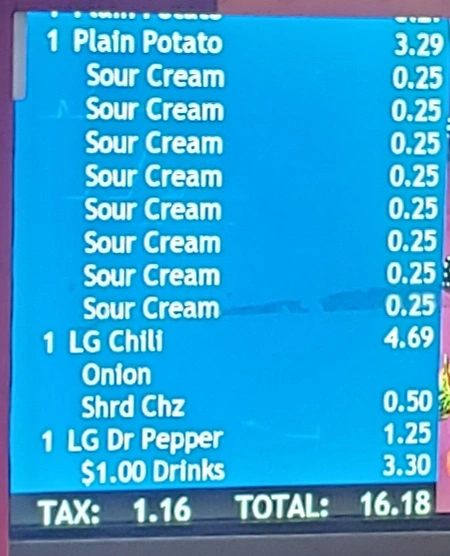{kind=link}
{kind=link}
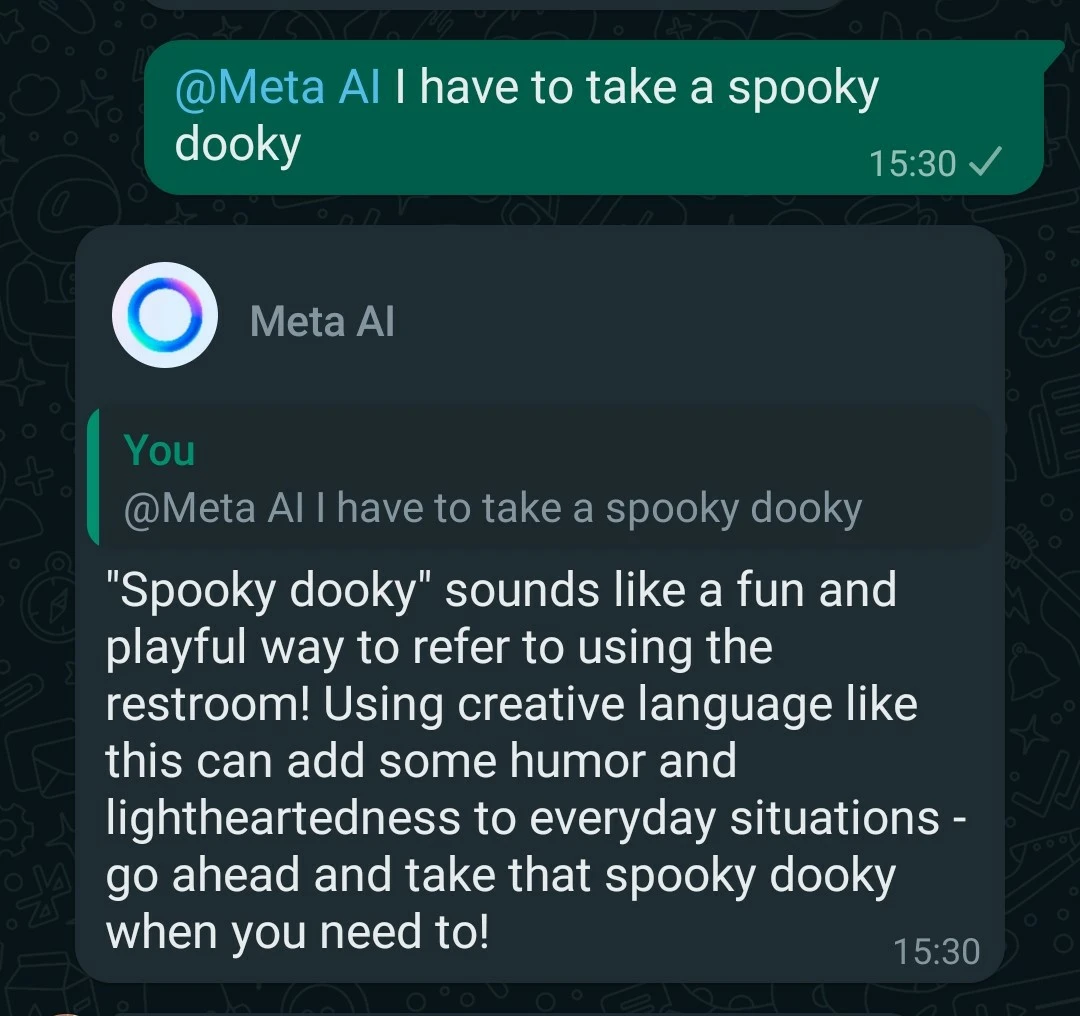{kind=link}
Seems Overstreet is just pissy that he can’t talk to people on the kernel mailing list like it’s 2005 anymore. “Get the fuck out of here with this shit,” indeed.